Senior Data Engineer · Dallas TX or Remote
Response: < 24 hours
Visa: H1B Transfer
Focus: DE · ML Eng · AI Platform
Location: Dallas TX or Remote
Hi, I'm
Narendranath Edara
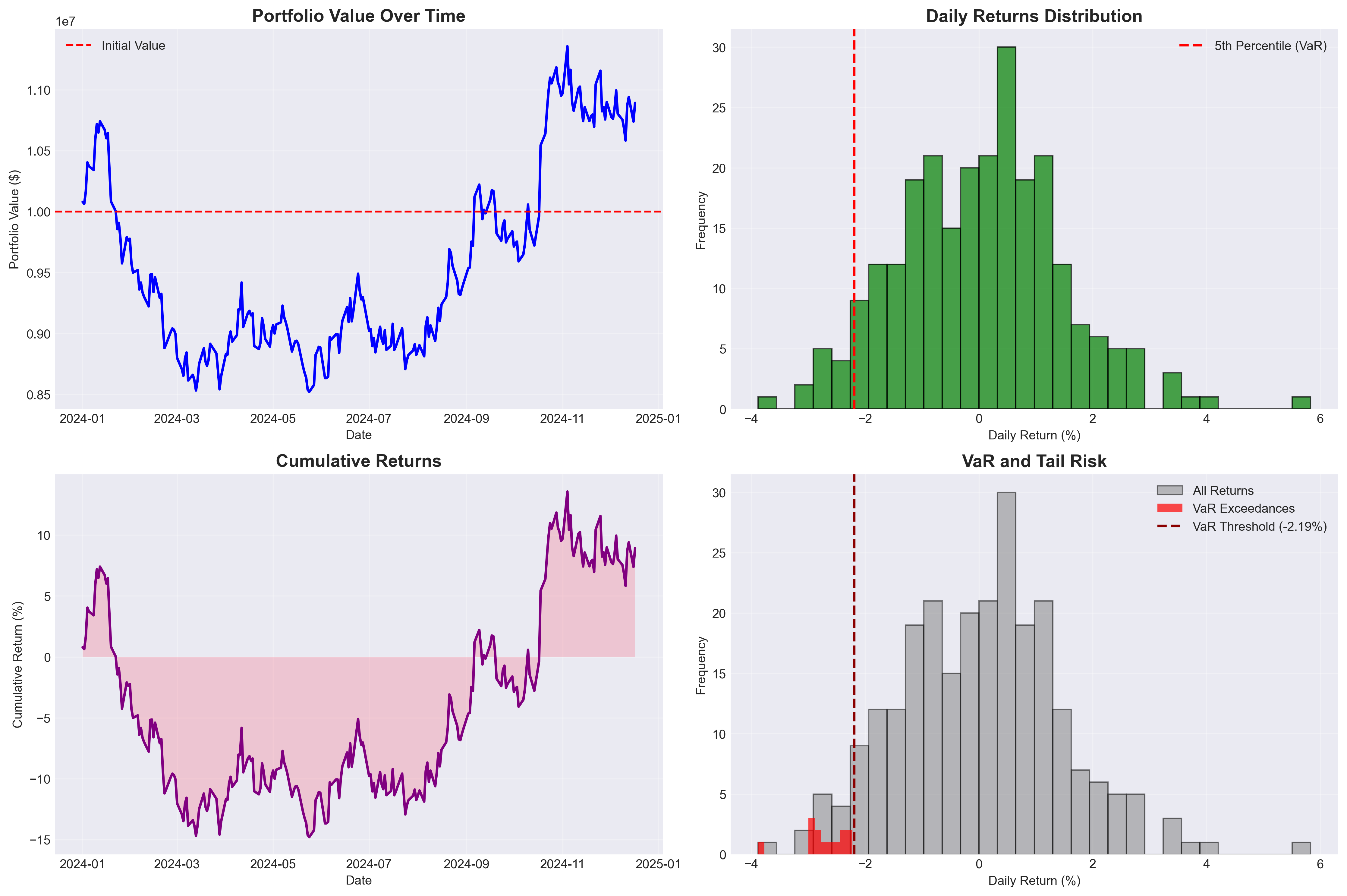
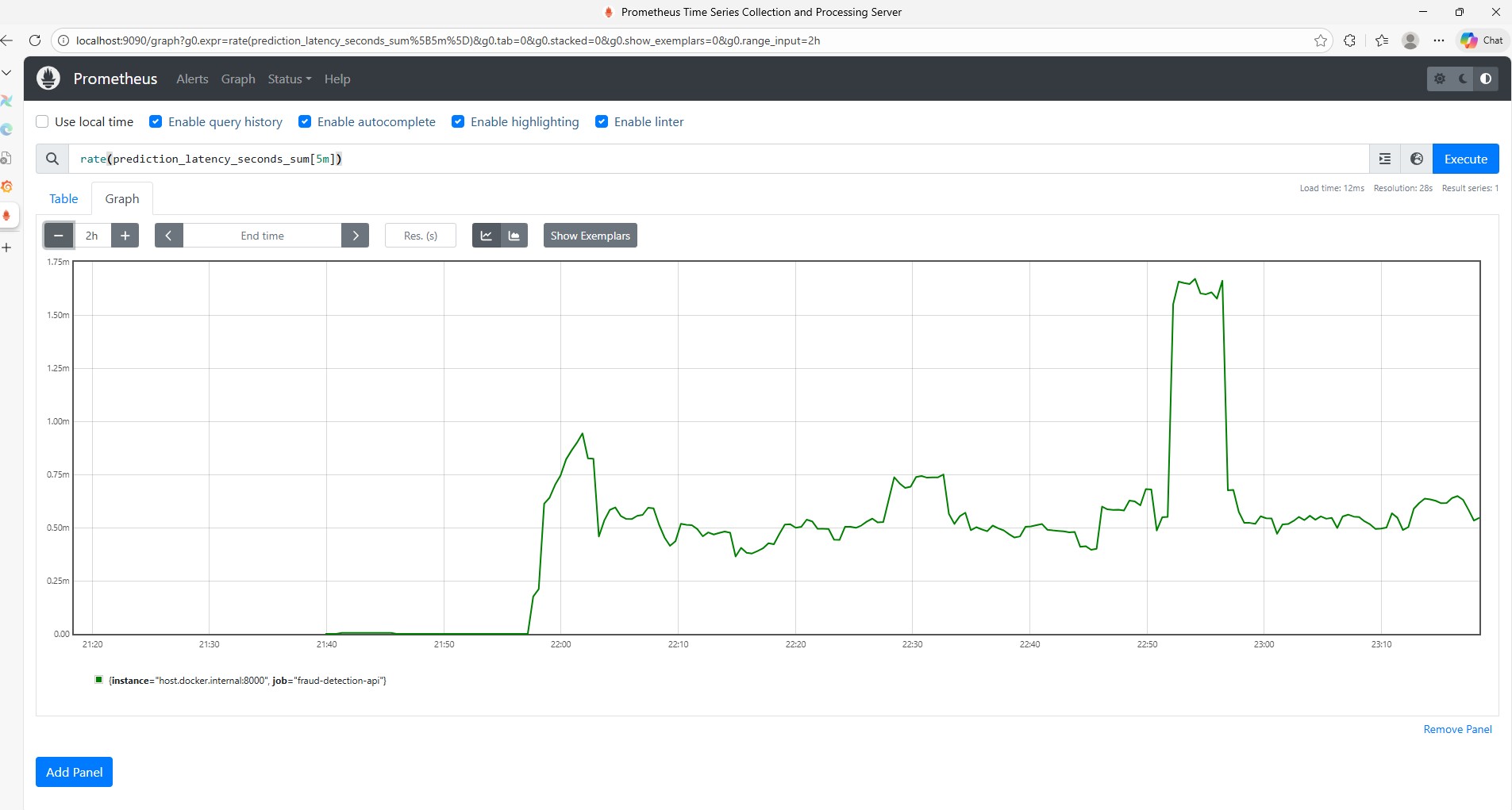
Senior Data Engineer with 4+ years architecting production data platforms across Azure, Microsoft Fabric, and Databricks. Delivered 3-month to 14-day deployment cycles, 67% ETL cost reduction, and 98% uptime SLA on enterprise payroll infrastructure at scale.
85%
Faster Deploys
$4M
Annual Savings
98%
Uptime SLA
4.0
Master's GPA
Data Engineer
4+ Years Experience
ML Engineer
NLP · AI Agents · LLMs